Streudiagramme
Dies ist die erste Übung aus einer Reihe von Übungen zu hydrologisch/metereologischen Datensätzen und deren Auswertung.
Einleitung
Statistische Gesetzmäßigkeiten lassen sich an großen Datensätzen am einfachsten beobachten. Daher werden wir uns als erstes einige Datensätze mit einer Großen Anzahl an observations (Beobachtungen bzw. Messeinträgen/-punkten) anschauen. Statistiker sagen auch oft “mit großem \(n\)”. Bei großen Datensätzen nähern sich die empirischen statistischen Kennwerte denen der Grundgesamtheit an, also den Werten die man theoretisch für eine unendliche Anzahl an Messwerten berechnen würde (für \(n\rightarrow \infty\)).
Wie wir später sehen werden gibt es eine Vielzahl von Methoden, um statistische Größen auch für kleinere Datensätze zu berechnen bzw. abzuschätzen. Hier müssen einige Ungenauigkeiten in Kauf genommen werden und je nach Fachbereich werden unterschiedliche Methoden bevorzugt. Diese Unterschiede in der Methodik (und auch die Subjektivität in der Methodenwahl) verschwindet bei großen Datensätzen. Außerdem werden die Formeln einfacher und die dahinter stehenden Gesetzmäßigkeiten klarer ersichtlich.
Verwendete Datensätze
Wir werden einerseits tägliche Klimadaten des Deutschen Wetterdienstes (DWD) verwenden. Diese sind frei im Internet erhältlich und können mit einer von uns geschriebenen R-Funktion namens getDWDdata() herunter geladen werden. Dieser Datensatz enthält unter anderem Niederschlagshöhe, Temperatur, Luftfeuchte, Sonnenscheindauer und Luftdruck. Mit diesen Werten kann man die Grasreferenzverdunstung (\(ET0\)) und damit die klimatische Wasserbilanz berechnen.
Vorgehen
Bevor wir Formeln verwenden, um statistische Kenngrößen zu berechnen, wollen wir eine sehr einfache Methode verwenden, um uns ein erstes Bild von unseren Daten zu verschaffen. Ein sogenannter scatterplot bzw. Streudiagramm zeigt die Verteilung der Messdaten in einer Punktwolke. In dieser Punktwolke kann man meistens schon eine Struktur erkennen. Z.B. eine Häufung von Messwerten in bestimmten Bereichen oder einen Trend, also einen mittleren Anstieg bzw. Abstieg der Messwerte. Interessant ist auch, wie verschiedene Messwerte miteinander korrelieren, d.h. miteinander kausal oder durch eine latente Variable (eine dritte Variable, die beide Variablen beeinflusst) verknüpft sind.
Oft kommt es vor, dass unwissentlich statistische Formeln angewendet werden, für dessen Anwendung die Vorraussetzungen nicht gegeben sind (z.B. Normalverteilung der Messwerte). Oder aber statistiche Eigenschaften werden übersehen, weil sie nicht berechnet wurden. Ein Blick auf das Streudiagramm eines Datensatzes gibt oft schon deutliche Hinweise, welche Art von Statistik man anwenden darf und sollte. So kann man z.B. schnell erkennen, ob die Daten einen Trend oder Periodische Muster enthalten. In diesem Falle müsste man seine Auswertung anpassen, also z.B. Trend und Zyklus vorher heraus rechnen bzw. andere Formeln für die Auswertung verwenden.
Arbeitsschritte
Bitte öffnet RStudio immer, indem ihr auf die .Rproj Datei in eurem Übungsordner klickt. In unserer ersten Übung habe ich euch gezeigt, wie man diese anlegt. Nur wenn ihr diese Projektdatei ladet, weiß RStudio in welchem Ordner ihr arbeiten wollt. Außerdem wird mit dieser Datei der Stand eurer letzten Berechnungen geladen, ihr könnt also dort weiter arbeiten, wo ihr im Projekt zuletzt aufgehört habt.
Beginnen wir nun mit der Übung:
Installation getDWDdata()
Die Installation müsst ihr natürlich nur einmal durchführen.
install.packages("devtools")
library(devtools)
install_github("nFrechen/RgetDWDdata", ref="Lehre")Zusätzlich installieren wir noch ein Paket, dass wir später gut gebrauchen können:
install.packages("maps")Daten laden
Bevor die Funktionen im Paket RgetDWDdata verwendet werden können muss das Paket mit dem library()-Befehl geladen werden:
# Paket laden:
library("RgetDWDdata")Nun können wir getDWDdata() verwenden um die Klimadaten der Station Cottbus herunter zu laden:
# Daten für Cottbus herunter laden:
Cottbus <- getDWDdata("Cottbus", historisch=NA)Schaut euch auch die Hilfeseite zu dieser Funktion an:
help(getDWDdata)
help(getDWDstations)Erster Blick auf die Daten
Was haben wir hier für Daten? Schauen wir uns die Daten als Tabelle an:
View(tail(Cottbus,50))| STATIONS_ID | MESS_DATUM | QUALITAETS_NIVEAU | LUFTTEMPERATUR | DAMPFDRUCK | BEDECKUNGSGRAD | |
|---|---|---|---|---|---|---|
| 54510 | 880 | 2016-03-16 | 1 | 4.1 | 5.5 | 2.5 |
| 54610 | 880 | 2016-03-17 | 1 | 3.3 | 5.4 | 0.2 |
| 54710 | 880 | 2016-03-18 | 1 | 2.6 | 6.4 | 5.1 |
| 54810 | 880 | 2016-03-19 | 1 | 5.2 | 7.1 | 7.6 |
| 54910 | 880 | 2016-03-20 | 1 | 5.2 | 7.3 | 7.9 |
| 55010 | 880 | 2016-03-21 | 1 | 5.6 | 7.6 | 7.5 |
| LUFTDRUCK_STATIONSHOEHE | REL_FEUCHTE | WINDGESCHWINDIGKEIT | LUFTTEMPERATUR_MAXIMUM | |
|---|---|---|---|---|
| 54510 | 1023.09 | 70.13 | 3.5 | 9.5 |
| 54610 | 1018.78 | 72.58 | 1.3 | 12.3 |
| 54710 | 1009.52 | 86.29 | 2.3 | 5.0 |
| 54810 | 1009.66 | 80.83 | 1.7 | 9.6 |
| 54910 | 1005.06 | 82.58 | 3.8 | 6.4 |
| 55010 | 1003.46 | 83.04 | 3.9 | 9.3 |
| LUFTTEMPERATUR_MINIMUM | LUFTTEMP_AM_ERDB_MINIMUM | WINDSPITZE_MAXIMUM | NIEDERSCHLAGSHOEHE | |
|---|---|---|---|---|
| 54510 | -2.4 | -4.9 | 9.8 | 0.0 |
| 54610 | -4.3 | -6.5 | 5.6 | 0.0 |
| 54710 | -2.4 | -5.2 | 10.5 | 0.9 |
| 54810 | 2.1 | -1.9 | 6.2 | 0.0 |
| 54910 | 3.8 | 3.2 | 12.1 | 0.8 |
| 55010 | 3.1 | 1.4 | 13.3 | 2.1 |
| NIEDERSCHLAGSHOEHE_IND | SONNENSCHEINDAUER | SCHNEEHOEHE | |
|---|---|---|---|
| 54510 | 0 | 10.333 | 0 |
| 54610 | 0 | 10.833 | 0 |
| 54710 | 4 | 1.950 | 0 |
| 54810 | 4 | 2.983 | 0 |
| 54910 | 4 | 0.000 | 0 |
| 55010 | 4 | 0.450 | 0 |
Schauen wir uns zwei Ausschnitte aus den Zeitreihen an. Der Übersichtlichkeit halber benutzen wir nur die Daten der letzten 6 Jahre.
n <- nrow(Cottbus)
JahresAuswahl <- (n-365*6):n # Auswahl der letzten vier Jahre
plot(LUFTTEMPERATUR~MESS_DATUM, Cottbus[JahresAuswahl,], type="l")
plot(NIEDERSCHLAGSHOEHE~MESS_DATUM, Cottbus[JahresAuswahl,], type="l")
Streudiagramm
Nun entfernen wir den direkten Zeitbezug der Messwerte und schauen uns ein erstes Streudiagramm an. Dazu berechnen wir den Tag des Jahres für jede Messung:
Cottbus$JAHRESTAG <- yday(Cottbus$MESS_DATUM)
plot(LUFTTEMPERATUR~JAHRESTAG, data=Cottbus[JahresAuswahl,], pch=20, cex=0.5)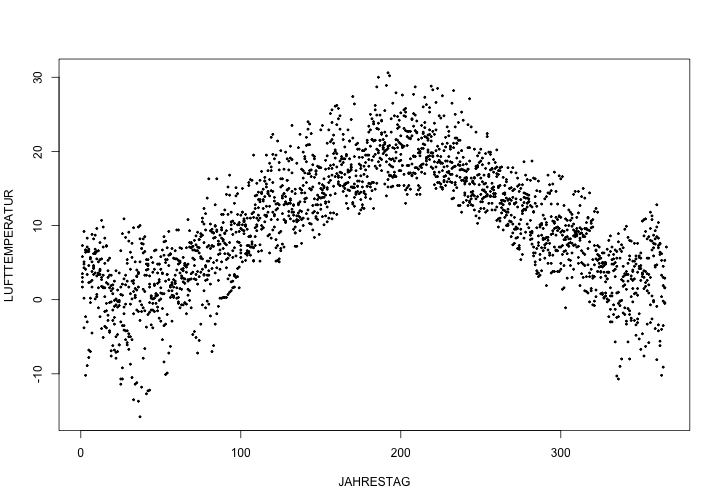
Deutlich ist der Zyklus in den Temperaturdaten sichtbar, der auch schon in der Zeitreihe deutlich wurde.
Wer einen Leistungsstarken Rechner hat kann diesen Plot für den gesamten Datensatz darstellen. Dazu entfernt man den Eintrag JahresAuswahl aus den eckigen Klammern oder entfernt die eckigen Klammern und ihren Inhalt insgesamt. Eventuell lohnt es sich auch die Plotsymbol Größe auf cex=0.1 zu verkleinern.
Erzeugen wir nun eine Übersicht aller Streudiagramme aller Daten, die man für die Klimadaten erzeugen kann. Ein paar Spalten werden wir nicht in die Übersicht mit hinein nehmen. Daher machen wir hier eine Spaltenauswahl:
SpaltenAuswahl <- c("LUFTTEMPERATUR", "DAMPFDRUCK", "BEDECKUNGSGRAD", "LUFTDRUCK_STATIONSHOEHE", "REL_FEUCHTE", "WINDGESCHWINDIGKEIT", "NIEDERSCHLAGSHOEHE", "SONNENSCHEINDAUER", "SCHNEEHOEHE", "JAHRESTAG")
plot(Cottbus[JahresAuswahl,SpaltenAuswahl], pch=20, cex=0.1)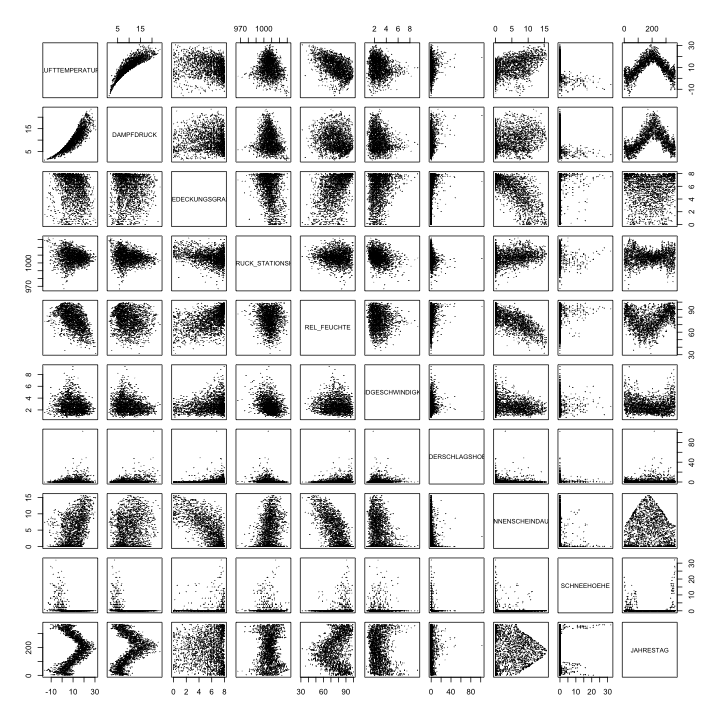
Zu jedem der in der Übersicht gezeigten Streudiagrammen könnt ihr eine eigene Abbildung erzeugen. Dazu ersetzt ihr einfach im folgenden Code die Variablennamen:
plot(LUFTTEMPERATUR~JAHRESTAG, data=Cottbus[JahresAuswahl,], pch=20, cex=0.5)Bitte schaut euch zumindest die folgenden Streudiagramme an:
- Sonnenscheindauer im Jahresverlauf
- Schneehöhe mit der Temperatur
- Dampfdruck gegen Temperatur
- Relative Feuchte im Jahresverlauf
- Relative Feuchte zu Sonnenscheindauer
- Niederschlag im Jahresverlauf
- Windgeschwindigkeit im Jahresverlauf
Was können wir in den Streudiagrammen beobachten?
- Trendartige Zusammenhänge bzw. positive oder negative Korrelation zwischen zwei Variablen (z.B. relative Feuchte zu Sonnenscheindauer)
- Grenzwerte (z.B. maximale Sonnenscheindauer im Jahresverlauf oder Schneehöhe in Abhängigkeit von der Temperatur)
- Zyklische Schwankungen:
- Veränderung des Mittelwerts bei gleichbleibender Streuung (z.B. Lufttemperatur im Jahresverlauf)
- Veränderung der Streuung bei gleichbleibendem Mittelwert (z.B. Luftdruck im Jahresverlauf)
- Veränderung von Streuung und Mittelwert (z.B. relative Feuchte im Jahresverlauf)
Eine Streudiagramm ist für die Hydrologie von besonderer Bedeutung. Schauen wir uns das Streudiagramm zwischen Temperatur und Dampfdruck an. Wir werden in diesem Falle nicht nur die Daten der letzten 6 Jahre verwenden, sondern den gesamten Datensatz.
plot(LUFTTEMPERATUR~DAMPFDRUCK, data=Cottbus, pch=20, cex=0.1)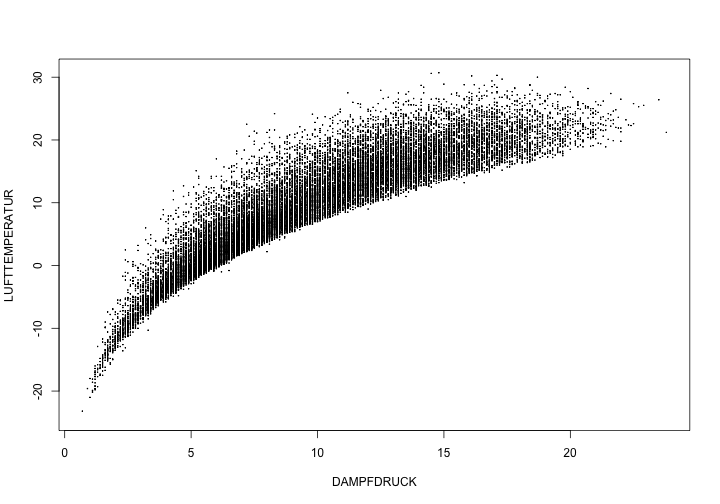
Das Streudiagramm zeigt an der einen Seite eine deutliche Grenze. Diese Grenze beschreibt eine Kurve die zuerst stark ansteigt und bei höhren Lufftemperaturen langsamer ansteigt. Die obere bzw. linke Seite der Punktwolke scheint eher “ausgefranst”. Hier lässt sich keine klare Grenze erkennen.
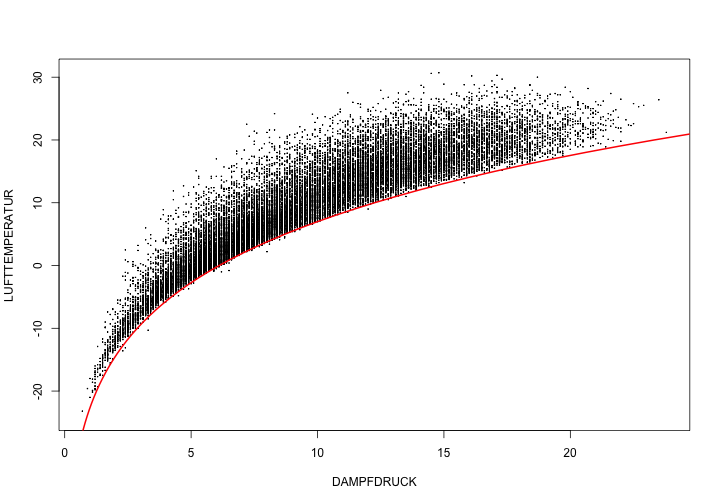
Wodurch entsteht also die Untere Grenze? Die Grenze kann durch folgende Formel beschrieben werden (siehe rote Kurve im nächsten Plot):
\[e_s(T)=6.11\cdot e^{\frac{(17.62T)}{(243.12+T)} }\]Was diese Formel bedeutet werden wir in der nächsten Übung besprechen.
Die nächste Übung in dieser Serie ist die Übung zur Grasreferenzverdunstung.